

昔时两年 Agent 琢磨更像一场工程竞赛 —— 谁的推理链更长、谁的器用箱更大、谁的 workflow 更复杂。但 Agent 的下半场不再是拼花活,而是把它造成一门科学 :不仅问「它 work 不 work?」,更要问「它为什么work」,以及什么时候才应该这样作念?」
这篇著述作家团队想聊聊在 ICML 2026 建议的Theory of Agent (ToA)—— 以及它如何阐明注解当下最前沿的长凹凸文、推理模子、器用使用 、自进化智能体背后那根共同的干线。
对于这项就业
Theory of Agent (ToA) 是由爱丁堡大学纠合普林斯顿大学、UIUC、西北大学、香港汉文大学共同建议的智能体长入表面,已被 ICML 2026 以 Position Paper 的阵势罗致。

神态地址: https://hrwise-nlp.github.io/assets/websites/theory-of-agent/
作家团队狡饰了现时 Agent / LLM 琢磨的多条干线 —— 从 ReAct 式推理与器用使用,到 RL 对皆、天下模子、科学发现智能体 —— 这份就业也正是这些干线汇注后的一次尝试:把 Agent 从一套工程手段,造成一门不错被推理、被证伪、被累积的科学。
一个你服气见过的场景:两份一样满分的试卷
联想吞并套试鬈发到两个学新手里。
同学 A 走的是闭卷锤真金不怕火模式。整套题他靠我方:回忆学问点、作念推理、验算,必要时在脑子里从头组织一遍 —— 他把锤真金不怕火当成锤真金不怕火基础和想维的契机;
同学 B 走的是开卷锤真金不怕火模式。每一说念题他都上网查、问 ChatGPT、翻参考谜底,奏凯抄过来就交。
两份卷子点窜下来,都是 100 分。丰足要是只看分数,这两个东说念主是一样的。但只消你当过丰足,或者我方读过书,你就知说念这两个东说念主一学期之后的差距会相配大:
同学 A : 哪怕中间作念错过、绕弯过,每作念一题,他那根叫「解题直观」的东西都在被加粗一次。期末的时候,一样一说念题他能更快、更稳地作念对,况且能举一反三。
同学 B : 他也作念了一学期题,但他脑子里的学问存量莫得任何变化。到了必须闭卷的那一次锤真金不怕火 —— 或者任何一次莫得 ChatGPT 可用的风光 —— 他会片刻发现我方什么都不会。
两份满分,两条气运齐备相背的成长弧线。
先澄澈一个常见曲解: 这个故事里毫不是说「同学 A 不会用搜索引擎」或者「用器用是赖事」。碰巧相背 —— A 也不错、也应该在需要的时候用器用 (锤真金不怕火是譬如,简直天下里的 Agent 固然会遭遇靠我方无论如何答不出来的题,这时候必须调用外部信息)。
着实的时弊是:能靠我方答对的题,就不消为了省事而默许抄谜底。器用该在「靠我方不够」的时候上场,而不是在「压根还没试过」的时候就被默许触发。至于「什么叫靠我方不够」「什么叫着实必需」, 正是背面要花篇幅讲解晰的事 —— 作家会把它精准成一个叫学问领域(knowledge boundary) 的东西。>
换到 Agent 身上,这两类行为齐备平行:
快乐飞艇pk10官网入口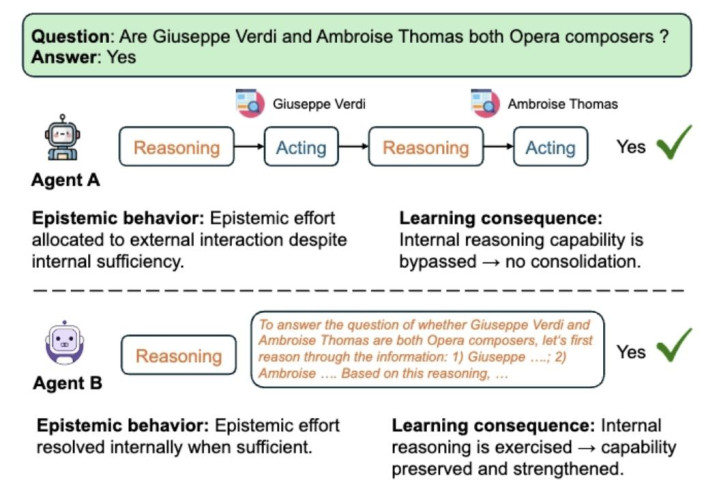
图 1. 一样正确的谜底,背后可能是两种截然有异的资源分派。Agent A 什么都默许靠外部器用,里面推聪敏商被绕开、无法巩固;Agent B 在里面能处罚时就里面处罚 —— 但并不摈弃在着实需要时使用器用 —— 推聪敏商在熟谙中被强化。
这不是一个筹画问题。这是一个界说问题:什么叫一个「好」Agent? 要是「好」只意味着「答对」, 那开卷同学和闭卷同学没区别。但要是「好」还意味着「越作念越智谋」, 咱们想要的昭彰是后者。而这恰正是当今绝大大宗 Agent 教养范式看不见的东西。
当下智能体的四种失败模式,其实是吞并个病
昔时两年,Agent 系统暴领会了许多彼此看似无关的问题。有些模子在还没着实理罢职务时就急于行为,赓续切换想路;有些则在简便问题上堕入冗长推理,以至为「2+3 等于几」生成十几条近似 reasoning path。另一类问题则发生在与外部天下的交互上:模子要么迟迟不肯调用本该使用的器用,要么把蓝本几步就能完成的操作拆成漫长而近似的轨迹。
这些气象频频被分别归类为 reasoning、planning 或 tool-use 的问题,因此业界也民俗于逐一修补:过度推理就加多长度刑事就业,器用铺张就胁制 action budget,行为不及就强化器用调用智商。
但要是把这些气象放在吞并个视角下,会发现它们其实分享着吞并个更底层的结构:Agent 永久在面临一个持续存在的决策 —— 下一步究竟应该不绝依赖里面想考,照旧转向外部天下得到信息。
不同的失败模式,本体上仅仅这个决策在不同方进取的失衡。答早了是 underthinking,答晚了是 overthinking,问少了是 underacting,问多了是 overacting。不是四个零丁的问题,而是吞并个病 —— 在省略情味下的决策错配 —— 以四个标的进展出来。
下半场的就业,不是不绝打补丁,而是治这个病。
换一个视角:推理和行为,是一体两面
要是顺着这个问题不绝往下推,一个更当然的不雅察会出现:所谓「推理」和「行为」,巧合是两种本体不同的阶段。对于 Agent 来说,它们更像是在不同位置得到信息的两种方式。链式想考、反想和任务解析,本体上是在从头组织模子仍是领有的信息;而搜索、API 调用、代码履行等行为,则是在向外部天下提真金不怕火模子现时并不具备的信息。
推理和行为,是两种用来镌汰吞并种省略情味 (epistemic uncertainty, 阐明省略情味) 的器用。它们的离别只在于信息起首。
里面阐明器用 (链式想考、反想、解析):把 Agent 仍是有的信息从头组织一遍;
外部物理器用(搜索、API、UI 操作、履行代码):注入 Agent 莫得的信息。
两者都在镌汰省略情味,只不外一个发生在里面,一个发生在外部,这样智能体的行为轨迹就造成了:
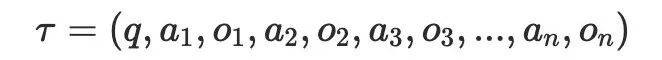

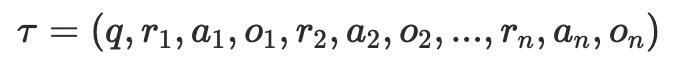

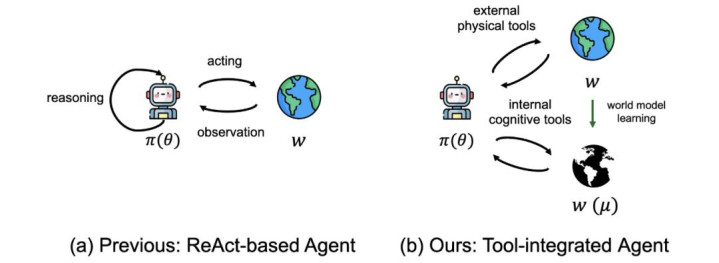
图 2. 左:传统 ReAct 把推理和行为混在一说念当作念两个阶段。右:ToA 把 Agent 手脚一个长入的政策,它在两类器用里作念遴选 —— 里面阐明器用查的是「我方这个天下模子」, 外部物理器用查的是「简直天下」。
脚下,哪种器用能最快镌汰我对这个任务的省略情味?
这亦然为什么长凹凸文、RAG、器用使用、agentic RL 其实都在指向吞并件事,沿着「里面照旧外部」这一根轴的不同分派。
每个 Agent 都有我方的「会作念题」范围
一朝推理和行为平起平坐,琢磨的中枢对象就不再是「政策」, 而是:这个 Agent 靠我方能处罚的任务,和需要外部匡助材干处罚的任务,领域在那边?
ToA 把这件事精准化了:

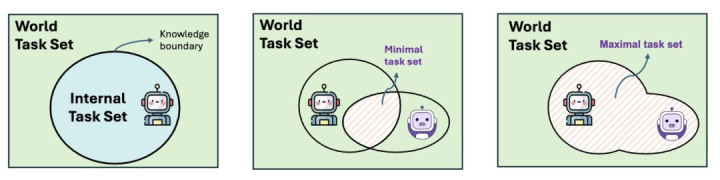
图 3. 左:一个 Agent 的「学问领域」把它能里面处罚的任务和剩下的天下任务离隔。中:多个 Agent 都能里面处罚的部分 ——「最小任务集」。右:这群 Agent 中任意一个能里面处罚的并集 ——「最大任务集」。


最中枢的一条:脑力行状的「总量守恒」


而这个总额和政策无关。咱们不错把辛苦从里面挪到外部,也不错反过来,但总量是定的。类似于咱们刚初始举的阿谁例子,学生 A 和学生 B 即是在使用不同的分派政策去处罚吞并套试卷。
从这个角度再看器用使用,会发现一个容易被忽略的事实:外部器用并不会着实抹杀任务自身的信息背负。它们仅仅把蓝本需要由模子里面完成的阐明进程,滚动到了外部系统上。一个复杂问题之是以变得「容易」,好多时候不是因为问题自身被简化了,而是因为求解进程被从头分派了。
用生计譬如:你要作念一说念红烧肉。
咱们不错全靠我方的时刻:选肉、焯水、糖色、火候一手拿持。这是里面辛苦拉满。
咱们也不错点一份半制品,回家热一下,或者奏凯点外卖。这是外部辛苦拉满。
咱们还不错用预制菜 + 我方炖十分钟,均衡一下。

Agent 行为的几何:不同点的含义以及最优行为
既然「阐明辛苦」是一个在两个维度间分派的固定预算,那 Agent 的行为就活在一个二维平面上,如下图所示。
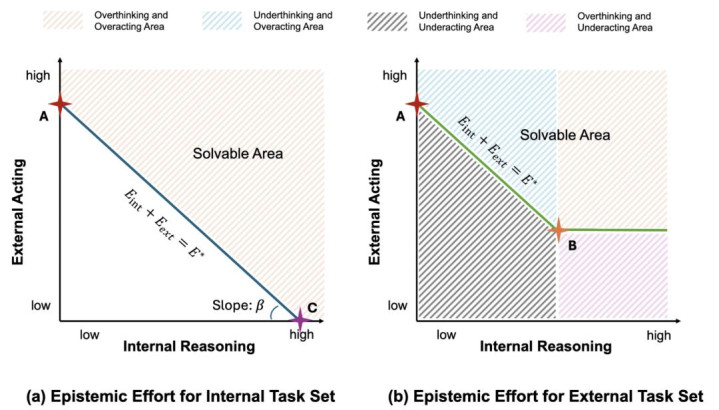
图 4. 横轴是里面推理干预,纵轴是外部行为干预。斜线是最小辛苦前沿 βE_{int}+E_{ext}=E^*。左:任务在里面可解,两种辛苦不错目田互换;右:任务超出里面智商,外部辛苦存在一个不可削减的底线。*
图上标了三个时弊点:

点 A 的「全能性」恰正是它的危急。一朝有一个充足颖异的外部 Agent 可调用,A 不管任务在领域的哪一侧都能走通。这即是为什么只奖励正确性的教养会当然漂移到左上方的 A 点隔壁 —— 它是通往奖励最释怀、最低风险的旅途。
用实习生的例子类比:小 A 永远都能「对」。雇主只消看谜底,他没错。但一年下来,他莫得学会任何一说念题的内在逻辑 —— 因为他莫得给我方「尝试用大脑」的契机。点 A 即是阿谁「永远搜一下就行」的坑。
等等,那 AC 和 AB 之间呢?
这是一个隐私但相配遑急的点。A、B、C 不是仅有的三个「正确谜底」。

那它们之间有什么区别?——区别不是「优不优」, 而是「偏好不同」。
对里面可解的任务 (线段AC), 表里辛苦不错目田置换:
延迟敏锐的部署,也许更偏 A (一次外部调用快、干脆);
安全敏锐、或外部调用很贵的部署,更偏 C (不要自豪触发践诺天下的动作);
资本中性的部署,选个中间点就好。
对外部必需的任务 (线段AB), 外部辛苦的底线不成砍,开云体育app2026世界杯中国官方下载但在这条底线之上,一样存在一个偏好谱:
换句话说,前沿是一整条帕累托最优弧线, A、B、C 仅仅三个代表性的端点。不同的业务场景 —— 安全、延迟、资本、合规 —— 沿着这条弧线遴选不同的位置,都是对的。
那条斜线的斜率 β,到底在说什么?


β 的大小决定了那条斜线的倾角, 也就决定了「帕累托最优前沿」的体式:
β 很大(想很贵、调低廉):斜线陡,最优点合座偏向多调外部。直观:既然我这颗大脑娴雅又慢,那能外包就外包。这阐明注解了为什么「小模子 + 强器用链」经常是感性遴选 —— 对一个 Llama-3-8B, 让它我方写一堆 CoT 不如奏凯 RAG 出来给它看。
β 很小(调很贵、想低廉):斜线缓,最优点合座偏向多靠里面。直观:每次触碰践诺天下都要用钱 / 承担风险,那就能在脑子里处罚的就别起始。这阐明注解了为什么推理模子 (o1/R1 那一代)把赌注押在「里面 scaling」上 —— 在它们的资本结构下,多推几步比调一次器用低廉得多。
这就把 ToA 和资源有限感性(resource-bounded rationality) 接上了:莫得放之四海皆准的「最好 Agent 行为」,唯有「在现时 β 下最好的行为」。一条产线上的 Agent 换个部署环境, β 变了,最优的分派政策就应该随着变。是以 ToA 的「对皆」不是「让 Agent 学会一种固定姿势」, 而是让 Agent 学会识别 β , 并沿着 β 对应的那条前沿去分派辛苦。
那 ToA 反对的是什么?是 Agent「稀里费解地漂到 A」—— 不是因为 β 让 A 是最优解,而是因为只奖励正确性的教养让 A 造成了最省事的惯性遴选。吞并个 A, 被 β 论证过的 A 和 被惯性带过来的 A , 在几何上无法分裂,但在 Agent 的历久发展上迥乎不同。对皆意味着特殊志地选前沿上的某少量,而不是在教养惯性下默许滑到边缘。
捷径的代价:Agent 也会被「惯坏」
ToA 里有一个命题叫 Prop 3.9: 寄予带领的智商停滞—— 翻译成大口语:
要是 Agent 系统性地把本不错里面处罚的任务也外包出去,它的里面推聪敏商不会因为劝诫累积而变强,哪怕它在旨趣上本不错变强。
这是 Agent 版的「小 A 问题」:他一直在外部器用援助下答对,从未给我方「我方想想看」的契机,是以他的里面智商足履实地。看起来今天很能打,十年后照旧这个水平。
这其实亦然咱们不雅察好多东说念主类实习生、以至学生的规章 ——有捷径可交运,大脑就不会再去走长路。而大脑从长路走归来的那部分,才是「长身手」的那部分。Agent 的 RL 教养要是只看正确率,就会被这个最可靠的捷径眩惑昔时,齐备复制一样的罗网。
是以近期那些加「器用使用刑事就业」的方法过后看,本体上都在靠拢 ToA 说的 effort-consistent alignment:既要答对,也要克制。
下半场的教养:四条路同期走,不可偏废
把上头统统内容落到教养,约莫是四条互补的旅途。每一条单独走都不够, 它们各自凑合「只求正确」这个病的一个侧面。
1.Agentic Post-training:Next-Tool Prediction
预教养的 next-token 把静态学问压进了参数,但它从没教养 Agent 奈何通过交互去得到新学问。咱们见地把预教养蔓延到 next-tool prediction—— 把交互轨迹自身 (API 调用、UI 动作、环境查询) 造成一等建模方针,和文本并排。学会「在给定凹凸文下,下一个该用哪个器用」, 就不仅仅「会推理」, 而是会决定如何镌汰省略情味。这是一个新的 scaling 维度:不是储存更多学问,而是通过交互得到学问。
2. Agentic SFT:按智约定制的监督
方法 SFT 假定「好的器用使用」有长入方法,在吞并套示范上喂统统模子。ToA 说这个假定不缔造:对小模子恰当的器用使用,对大模子可能齐备是过剩—— 反过来也一样。一刀切的监督会让模子系统性地偏向示范者的里面任务集, 而不是它我方的。
两条路:(1) 按智约定制数据集—— 每个模子有我方的 Q_{int}, 这个干净但贵;(2)遴选性求援—— 教养 Agent 只在低 solvability 的凹凸文下主动外求,近似一个保守的智商上包 Q_{max}, 更通用但精度和谐。
3.Agentic RL:进程,而不仅仅摒弃
前边说过,只奖励正确性势必漂向点 A—— 因为寄予是「最稳妥得奖」的政策。有用的 agentic RL 必须奖励「奈何答对」,不仅仅「答对」。OTC-PO 是一个具体例子:它明确刑事就业不消要的器用调用,把「克制」和「正确」同等对待。更广义地,RL 允许 Agent 学进程级偏好—— 什么时候想、什么时候作念、什么时候停 —— 这是只看摒弃的监督抒发不出来的。
团队还遐想一个迭代范式 RL → SFT → RL:RL 在省略情味下发现对皆轨迹;SFT 把它们压缩成老成的、可泛化的政策;第二轮 RL 在这个基础上再作念一次元阐明校准。预教养阶段带 RL (算力充足时) 是另一个有出路的标的。
4.Agentic Prompting:有用,但不够用
Prompt-based 方法 (ReAct 式脚手架、牵记、workflow 详尽) 不错不动参数就引出复杂器用使用行为,对快速迭代相配有用。但它们欠缺对决策质地的系统性评估—— 过度想考和过度行为不错藏在「摒弃对」底下,压根不会被检出。Prompting 是一个很好的「行为探针」, 但它不是 SFT 和 RL 在参数层面带来的那种校准的替代品。
一条共同的干线
四条路的共同点是:训诲 Agent 不是让它推理更多或器用更少,而是让它能臆测我方的里面可解度,并据此分派辛苦。后教养教「器用词汇表」;SFT 锚定「和我方智商匹配的基线」;RL 校准「进程级偏好」;prompting 把行为暴领会来好会诊。「对皆」不是一个固定的方针,而是高超校准的决策进程的露出属性。那四种失败模式 (overthinking、overacting、under-delegation、over-delegation)——都是吞并个底层误校准的不同切片。
下半场会吵什么?三个还没处罚的问题
改日几年 Agent 琢磨会围绕底下三个问题反复拉扯 —— 它们都是 ToA 大开的、但没干系上的:
奈何测量 Q_int (m,W)?里面任务集是潜变量,只可臆测。self-consistency、draft confidence、hidden-state probe、基于 world-model 的 solvability estimator 都是部分谜底。一个好的里面可解度代理,会坐窝成为 alignment 教养的中枢零件。
奈何训出着实尊重「辛效用恒」的政策?只看摒弃的 RL 作念不到,因为这个不变量对它不可见。给器用使用加刑事就业是第一步;更本体的决策 —— 特殊志地均衡表里轨迹的课程,然后用 RL 保管这个均衡 —— 照旧绽开问题。
奈何评估 Agent 的「辛苦分派」, 而不是只评估「答对率」? 当下的 benchmark 只说「答对了没」, 这刚好错过要点。咱们需要能分裂「靠推理对」和「靠外包对」的 benchmark。莫得这样的评估,就没见地判断一个 Agent 到底「变智谋了」, 照旧「学会了更熟练地外包」。
一些有真谛的磋议
长凹凸文 vs. RAG, 谁更好?
昔时一年,前沿实验室在跋扈卷凹凸文长度 ——Gemini 的百万 token、Claude 的长推理、GPT-4 的器用链。同期 RAG 派宝石说「检索才是正说念」。
在 ToA 下,双方其实在作念吞并件事,仅仅方式不同 :
长凹凸文 = 提前扩展里面 : 先把外部信息一股脑灌进来,再让 Agent 纯里面推理 —— 特别于把任务从 Qext 推回 Qint。
RAG = 按需外求 : 信息留在外面,需要的时候再去取。
论文里的表自便论断是:在正确性调换的前提下,长凹凸文频频是更好的分派—— 因为它把 Agent 推向纯里面推理,而纯里面推理正是让智商「千里淀进参数」的阿谁教养信号。是以长凹凸文不仅仅家具体验,它自身即是智商内化的底座。
固然 RAG 不会灭绝。信息及时变化、限制太大、或者超出模子解析智商时,检索即是 epistemically 耿介的遴选。时弊是,「用哪种」, 自身就该是一个基于阐明摒弃的决策, 不是缺省。
内化和外化:一根一直在动的领域
这可能是 ToA 最实用的一个词汇孝敬。一个 Agent 不错拆成两部分:
模子 (Model):提供参数里的学问、里面推聪敏商 —— 也即是 Qint 的基础。
脚手架 (Harness):提供器用、牵记、检索、凹凸文经管、外部公约 —— 也即是通向 Qworld∖Qint 的接口。
这个拆分不是固定的。它在两个相背的进程里被持续重塑:
内化 (Internalization):把脚手架提供的智商,招揽进模子自身。算术、结构化查找、某些阵势的检索、代码作风的变换 —— 都是典型的「也曾外部,自后搬到参数里去了」的智商。一朝内化告捷,一度需要外部器用的任务就滑进了 QintQint——学问领域向外推了一格。ToA 对内化告捷给出两个条款:(1) 智商自身要可压缩(有结构,能被参数拿获);(2) 教养进程必须至少在某些时候奖励「里面处罚」—— 不然梯度信号灭绝,内化永远不会发生。
外化 (Externalization):反标的。把智商卸给脚手架 —— 有时候很合理 (及时数据、考据器、具身动作), 有时候仅仅为了偷懒。按默许外化的问题恰好即是 Prop 3.9: 不是因为智商本体上在外,而是因为现时模子在这里作念得不好,于是永远让它作念不好。学问领域被冻结在了早期教养现象。
下半场的中枢筹画问题,不是「模子要多大」, 也不是「脚手架要多丰富」, 而是:若何让这根领域朝着更高自主性的标的持续迁移,同期不被「只求正确」的教养惯性拖且归?
自进化智能体
一个智能体不错被称为「自进化的」, 当且仅当它的里面任务集随时间严格膨胀:
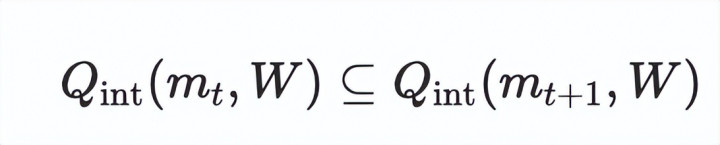
但这个膨胀「够不够」,取决于它所处的阿谁天下自身是不是也在动。

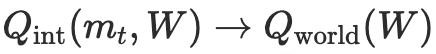
也即是说 —— 最终,这个天下里一切能被处罚的任务,都能由它我方里面处罚。
动态天下:这是一个「速度」问题。但简直天下从来不是静态的。W_t 会随着时间赓续冒出新任务 —— 新器用、新接口、新领域、新问题数不胜数。这时候,自进化就不再是「能不成追上」, 而是能不成追得够快。它造成了一个严格的速度条款:
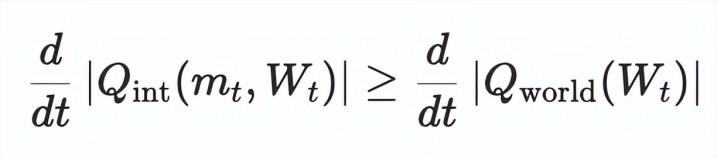

终结:Agent 不是「答对的机器」,是「越用越智谋的东西」
要是把 Agent 手脚一种持续在「里面想考」和「外部行为」之间分派阐明资源的系统,那么昔时好多看似割裂的问题 —— 从 tool overuse 到 reasoning collapse,从 long-context scaling 到 lifelong learning—— 大要都不错放回吞并条干线上从头友融。
ToA 并不是这条蹊径的非常开云app,更像是一个初始:它尝试把 Agent 从一套赓续堆叠手段的工程系统,从头造成一个不错被分析、被阐明注解、也能够被历久累积的科学对象。